Services applicatifs d'infrastructure
Avant de monter des services destinés aux utilisateurs, un minimum est requis. Il s'agit typiquement de : DNS, DHCP, LDAP, fournisseur d'identitié, reverse proxy, sauvegardes, éventuellement haute disponibilité, etc. Le plus important étant ce qui est en bas de la pyramide de Maslow (après le matériel et l'électricité) : la sécurité. Tout est "dockerisé".
Pérennité des données
Si l'uptime de mes services ne m'importe pas énormément, c'est autre chose en ce qui concerne la bonne conservation de mes données, dont certaines ont plus de 15 ans d'âge.
Pour définir une politique de sauvegarde/restauration des données, je me suis largement inspiré d'un article SRE de Google. Même si au final la solution retenue est simple. Mais elle est réfléchie.
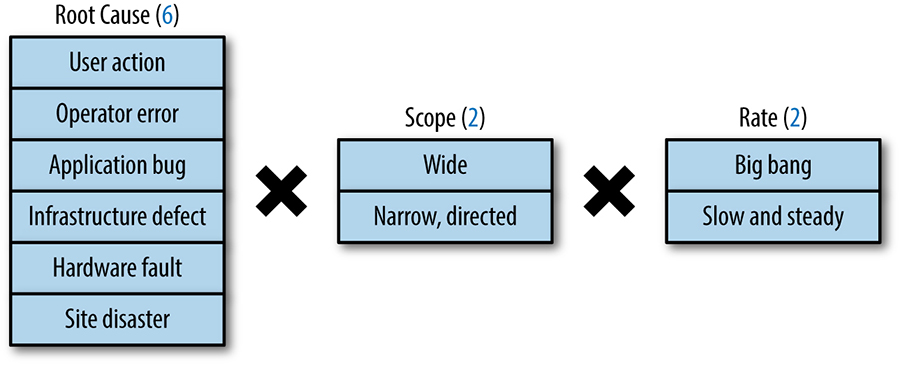
On-site online automated frequent backup
Les serveur principal est sauvegardé sur le serveur de backup. La configuration du serveur de backup est sauvegardée sur le serveur principal. Les ordinateurs des utilisateurs sont sauvegardés sur le serveur de backup.
Pour les serveurs, il s'agit d'une sauvegarde en mode fichier exclusivement. Pour les ordinateurs des utilisateurs, les données personnelles sont sauvegardées en mode fichier, et le volume système en mode bloc. Les sauvegardes en mode fichier sont réalisées avec restic tandis que celles en mode bloc sont faites par Veeam.
Dans tous les cas, les sauvegardes sont journalières pour le moment. En matière de rétention, pour Veeam, c'est assez rudimentaire. Je conserve les 14 derniers points de restauration. Pour restic, c'est plus élaboré. Plus on remonte loin dans le temps, plus les points de restauration se font rares et espacés.
Off-site offline manual infrequent backup
Pour la sauvegarde hors-site, censée assurer des sinistres généralement graves, j'ai longtemps voulu prendre une solution telle qu'Amazon Glacier. Cependant le choix a été vite fait au moment de choisir une solution. C'est ma connexion Internet et ses 1 Mb/s de bande-passante montante qui ont choisi. En outre, le caractère nomade de la jeune génération à laquelle j'appartiens et la couverture en très haut débit en France (voire du monde) en zones peu denses que j'affectionne , font qu'il n'est pas impossible que dans un futur proche je vienne à déménager d'un logement fibré à un non-fibré.
La meilleure solution que j'ai trouvée, qui me semble décente, est d'avoir une troisième copie de mes données dans ma voiture. Une copie chiffrée bien sûr. La température de stockage n'est pas tant un problème, même l'été. Les vibrations m'inquiètent plus mais en tout cas les 3 disques de 4 To (en RAID 5 soft) sont dans un emballage spécialement adapté au transport de disques durs.
DNS / DHCP
Forcément j'ai des adresses IPv4 privées, et il y a besoin de mettre un nom DNS dessus. J'ai donc un serveur DNS autoritaire pour les zones correspondant à mes noms de domaine. Bien entendu, pour accéder à un service donné avec un nom DNS, le nom DNS est le même qu'on se trouve dans le réseau interne ou externe. Au niveau de l'implémentation, j'ai choisi dnsmasq mais je rencontre quelques soucis et suis en train de migrer vers Bind.
Même si j'ai un serveur DNS autoritaire pour mes noms de domaine, servant dans le réseau interne pour les adresses IP privées, ce n'est pas celui que contactent les utilisateurs quand ils sont dans le réseau interne. En réalité, il contacte un autre serveur DNS que j'héberge, qui sert principalement de forwarder mais dispose de quelques fonctions intéressantes comme une bonne observabilité concernant les requêtes, du blocage de publicité, et le support de DNS-over-TLS. Il s'agit d'AdGuard Home. Ce dernier est configuré de manière à forwarder les requêtes DNS concernant mes domaines vers le serveur DNS autoritaire. Le reste du temps les requêtes sont transférées à un serveur DNS public connu. Par ailleurs, AdGuard Home est hautement disponible grâce à anycast. Il est déployé sur les deux serveurs. Voir section réseau pour plus d'informations.
Concernant les requêtes DNS dans l'Internet, mon CDN, Cloudflare, s'en occupe.
Enfin, le serveur DHCP est dnsmasq.
Reverse proxy
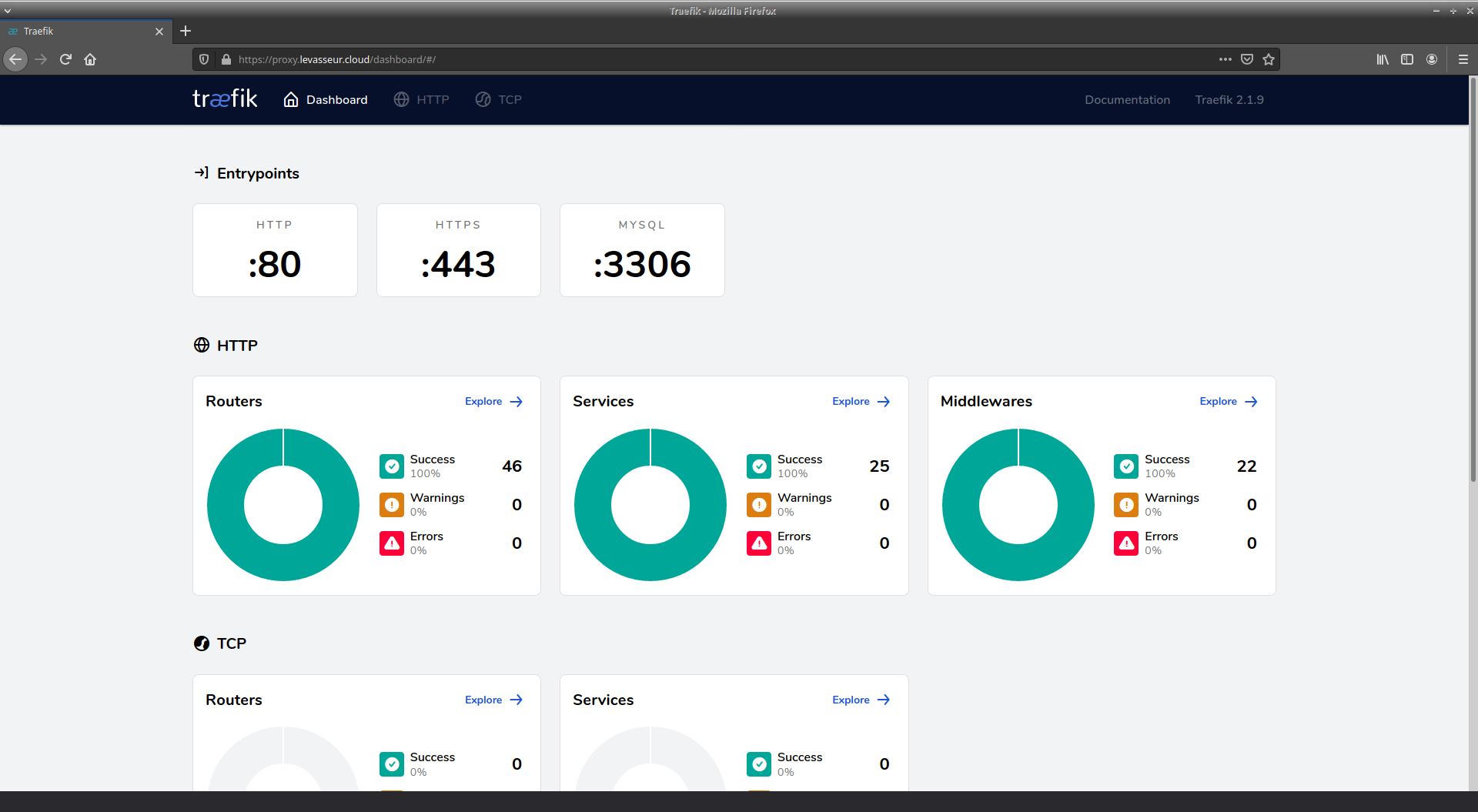
Mes services fonctionnant en HTTP sont accessibles via un reverse proxy, Traefik. Il y a plusieurs avantages à cela. Cela me permet avant tout d'avoir plusieurs "sites Web", avec des noms de domaines différents mais surtout : une seule adresse IP publique (privée aussi d'ailleurs) étant donné que mon fournisseur d'accès Internet ne m'en attribue qu'une. De plus, la gestion automatisée des certificats X.509 est centralisée. Le reverse proxy s'en charge. La gestion des pages d'erreurs HTTP peut également être déléguée au reverse proxy. Enfin, ce point d'entrée unique vers les services HTTP est l'opportunité d'imposer (ou non) de s'authentifier pour accéder aux services. Cela permet notamment une authentification unique pour tous les services.
AA : authentification, autorisation
Traefik est capable de faire de l'authentification basique centralisée mais pas de single sign on (SSO). Il faut donc s'authentifier, certes avec un seul compte, à chaque service qu'on veut accéder.
Ce mécanisme d'authentification est déjà bien puisqu'il protège les services en backend. Néanmoins il n'est pas du tout user-friendly et le manque de SSO est ennuyeux. Il y a quelque chose à faire... Le but étant d'avoir une page Web de login tout simplement.
Traefik permet une authentification centralisée, dans le sens où il y a un compte pour accéder à n'importe quel service que Traefik sert. Mais pas "centralisée" dans le sens où l'authentification est propre au système informatique dans son ensemble, ce qui inclut Traefik et d'autres service non-HTTP. Idéalement, il faudrait un annuaire. C'est donc OpenLDAP qui se charge de cette mission.
Pour l'authentification dans un contexte Web, il existe des standards. Autant les utiliser. Ainsi j'ai choisi OpenID Connect, basé sur OAuth 2. J'ai dû trouver une solution pour "convertir" mon annuaire LDAP en fournisseur d'identité compatible OAuth 2. Keycloack était overkill, alors j'ai choisi Dex.
Reste à faire le lien entre Dex et Traefik. Pour cela, deux designs étaient possibles. J'ai choisi de demander à Traefik de forwarder l'authentification vers un tiers (Dex donc).
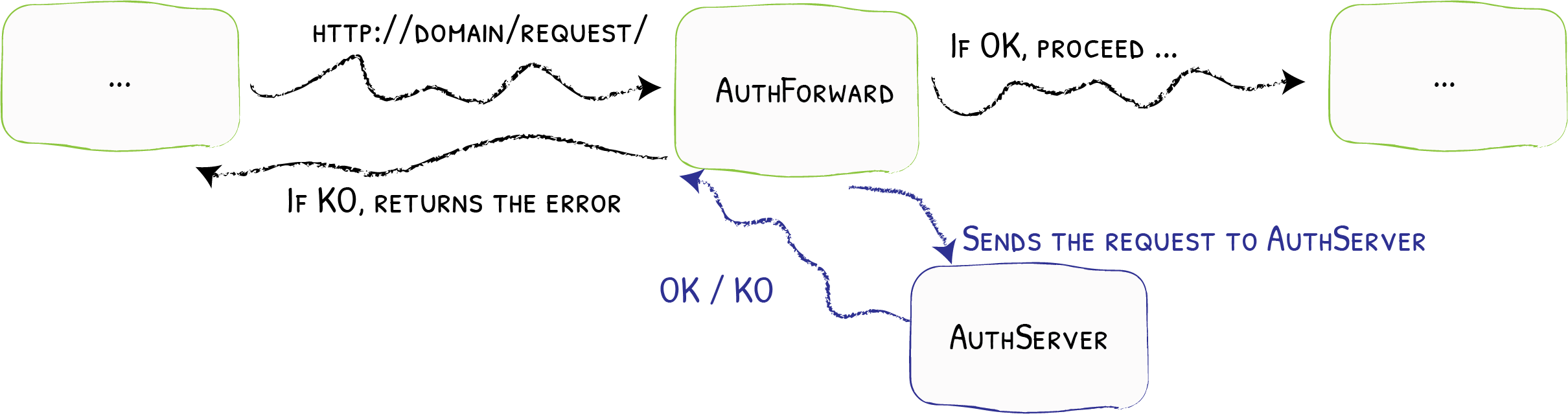
Néanmoins, Traefik ne joue pas non plus le rôle de client OAuth 2. Pour savoir si le tiers chargé de l'authentification a accepté l'authentification ou non, Traefik se base sur le code de retour HTTP dudit tiers. De plus, la plupart des applications ne sont pas compatibles avec OAuth 2, et c'est bien dommage. Comment faire alors ?
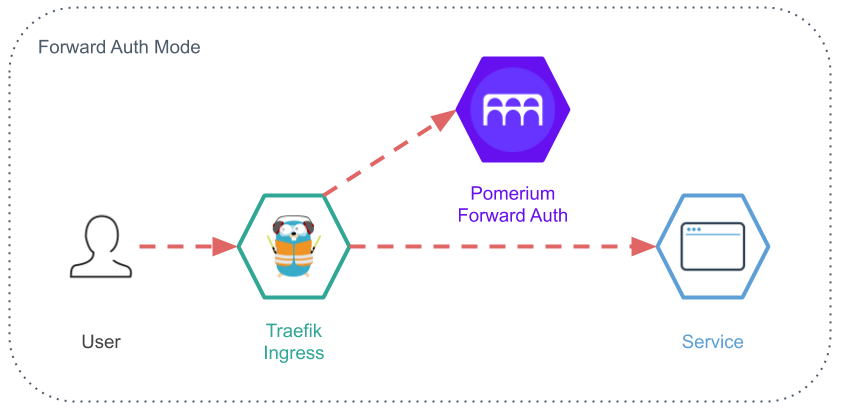
La solution consiste à mettre en place un proxy dédié à l'authentification et à l'autorisation. Il est l'intermédiaire entre l'application (qui potentiellement est tellement basique qu'elle n'a pas de notion d'utilisateur) et le serveur d'authentification, Dex. C'est ce proxy qui va imposer de s'authentifier en redirigeant l'utilisateur final vers le serveur d'authentification, et plus exactement son formulaire de login. C'est aussi ce proxy qui va implémenter le concept d'autorisation. Par exemple, un utilisateur est authentifié mais ne doit pas avoir le droit d'accéder à un service. Ce proxy là est dans mon cas Pomerium.

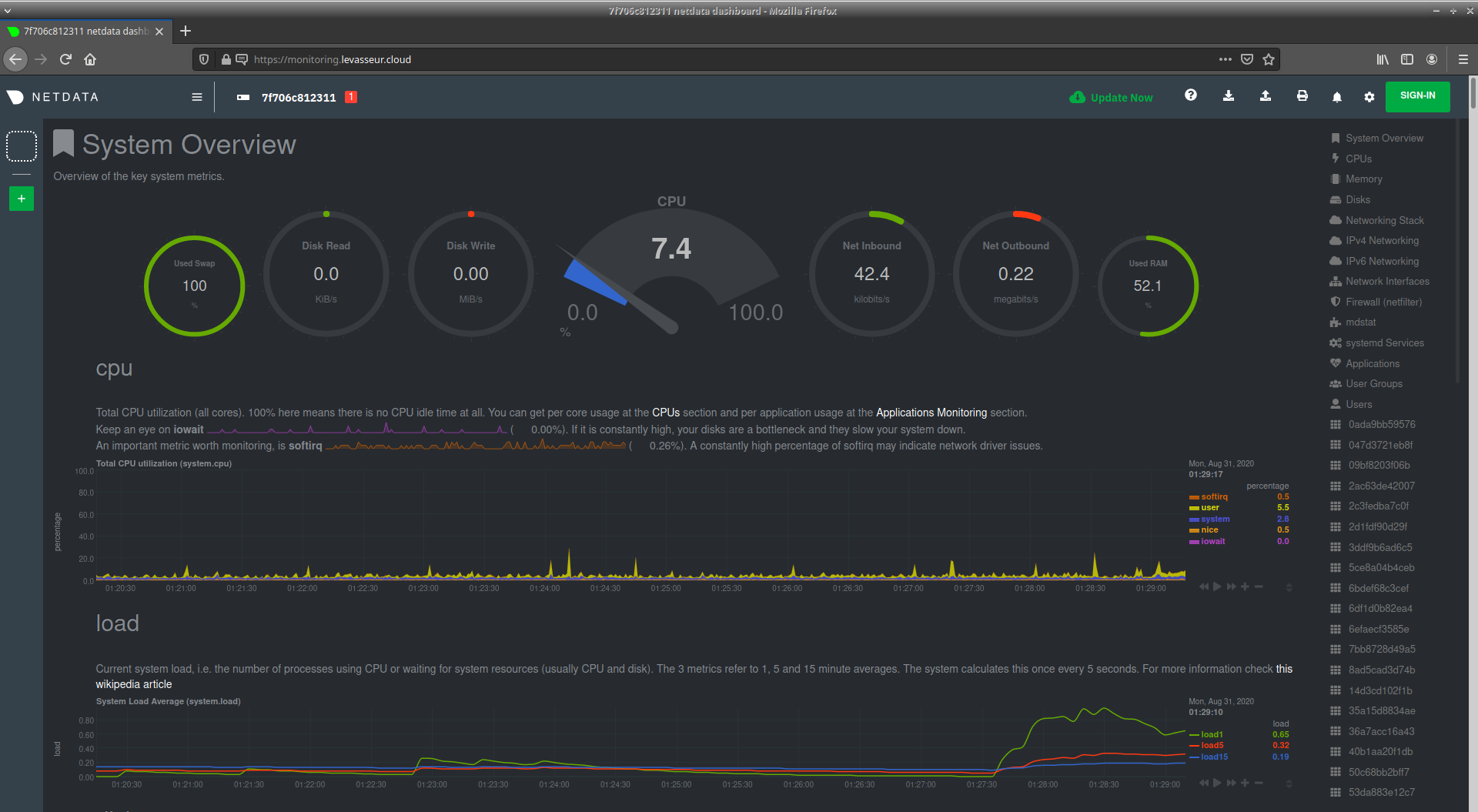
Supervision
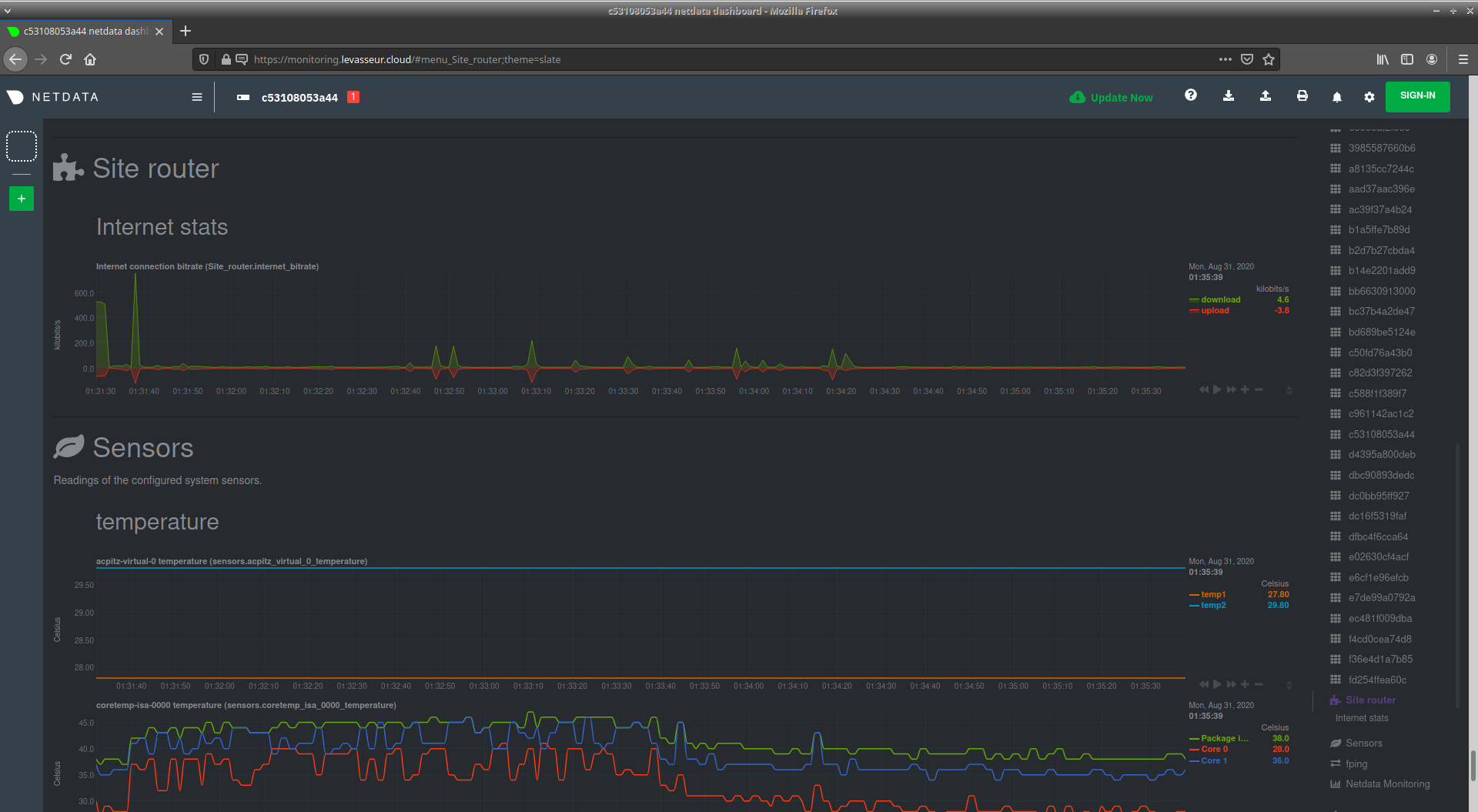
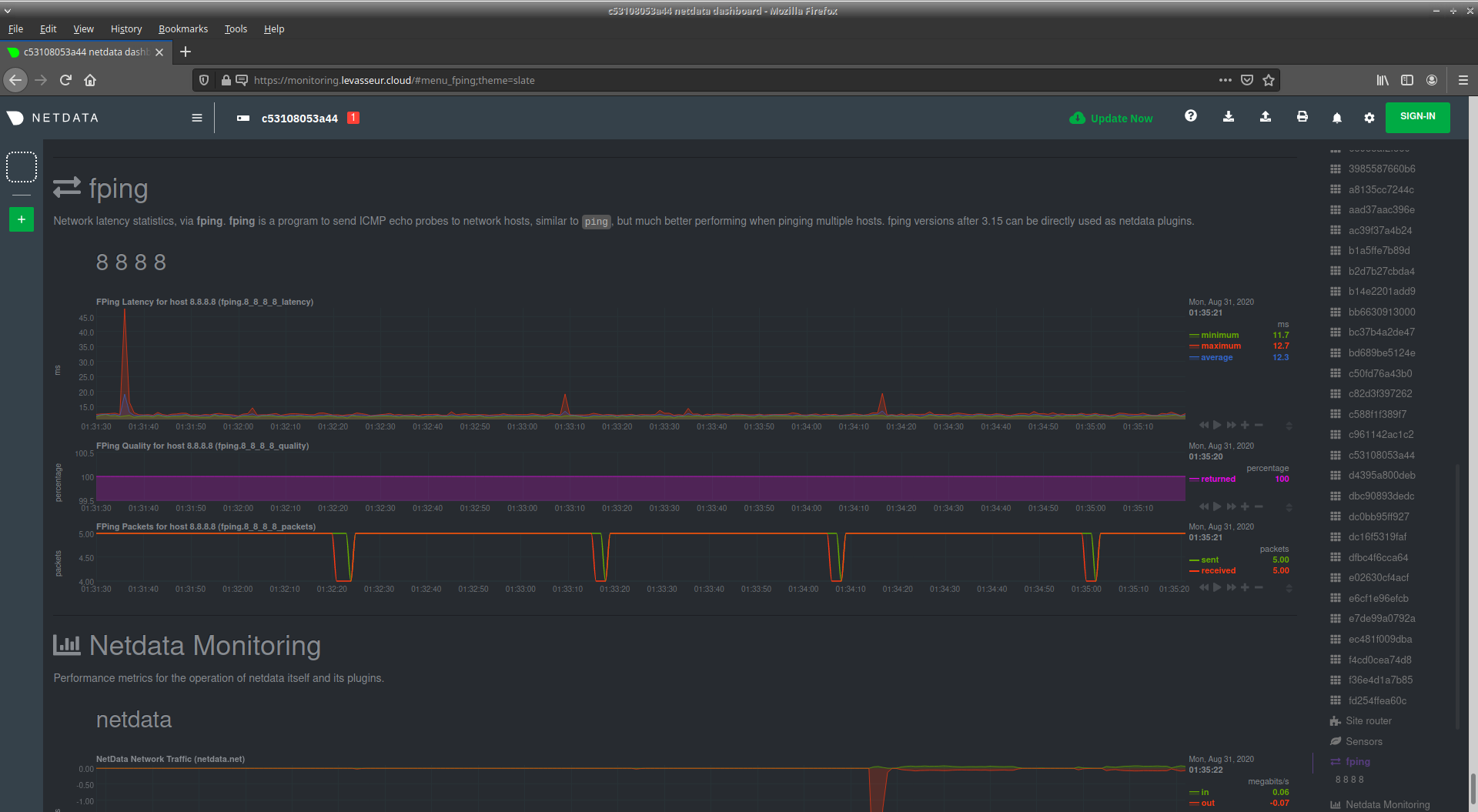
Ici j'utilise Netdata. C'est extrêment complet dans le sens où Netdata collecte un tas de métrique sur la machine sur laquelle il est installé. C'est une solution à base de graphs, mais avec également une notion d'alerting. Si par défaut Netdata supervise la machine locale, faute de connaître le reste du système informatique, Netdata est extensible et on peut aisément ajouter des graphs pour superviser tout et n'importe quoi, y compris des équipements accessibles en SNMP.
Pour ma part, chacun des deux serveurs a son Netdata, pour des raisons de simplicité. Néanmoins, sur le serveur principal, j'ai rajouté des graphs pour surveiller l'utilisation de ma bande-passante Internet et ma connectivité à Internet en terme de latence.

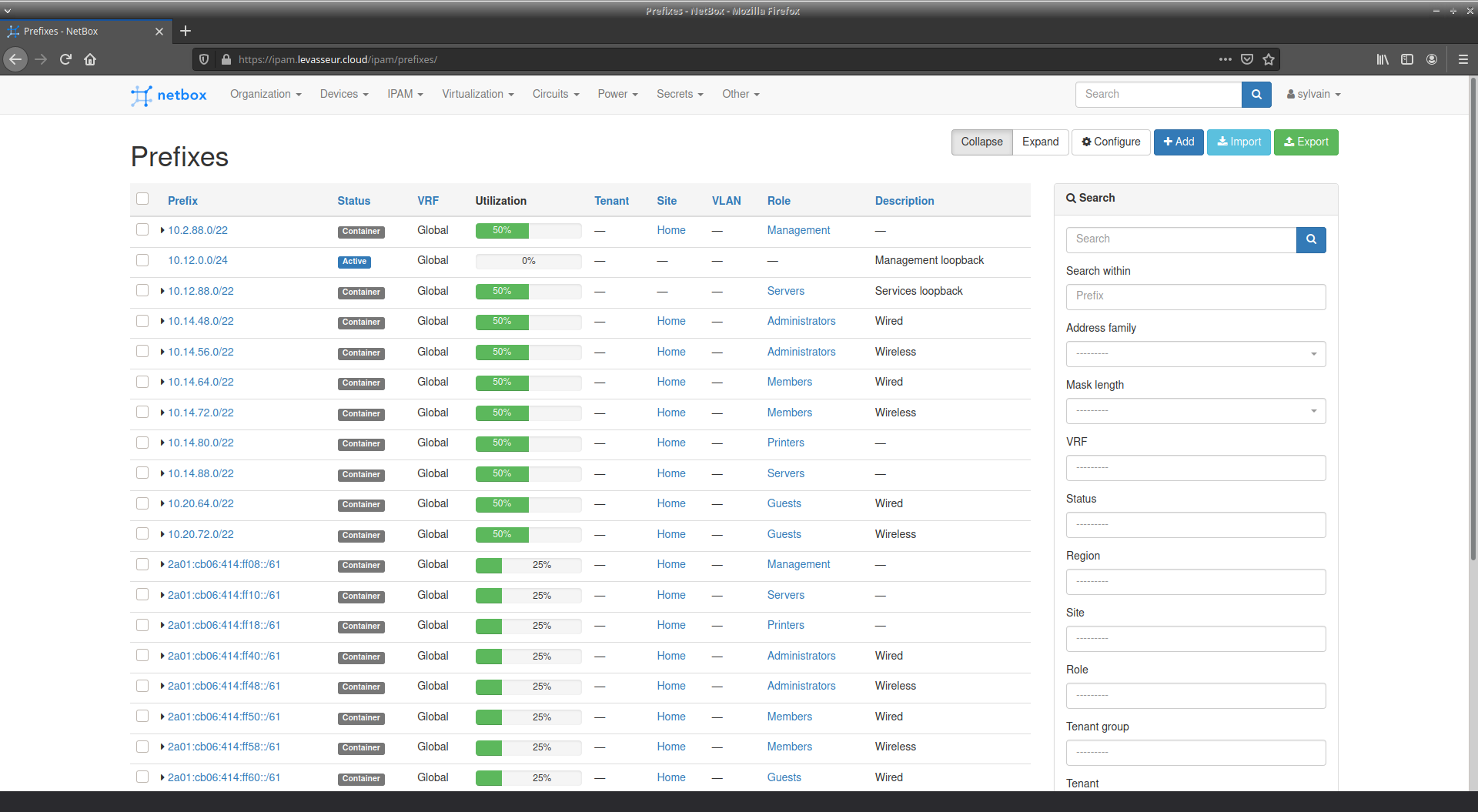
Gestion d'adresses IP (IPAM)
Pour faire l'inventaire de mes VLAN, adresses IP et équipements, j'utilise Netbox. Netbox peut s'intégrer assez facilement avec Ansible grâce à une API et des "webhooks".
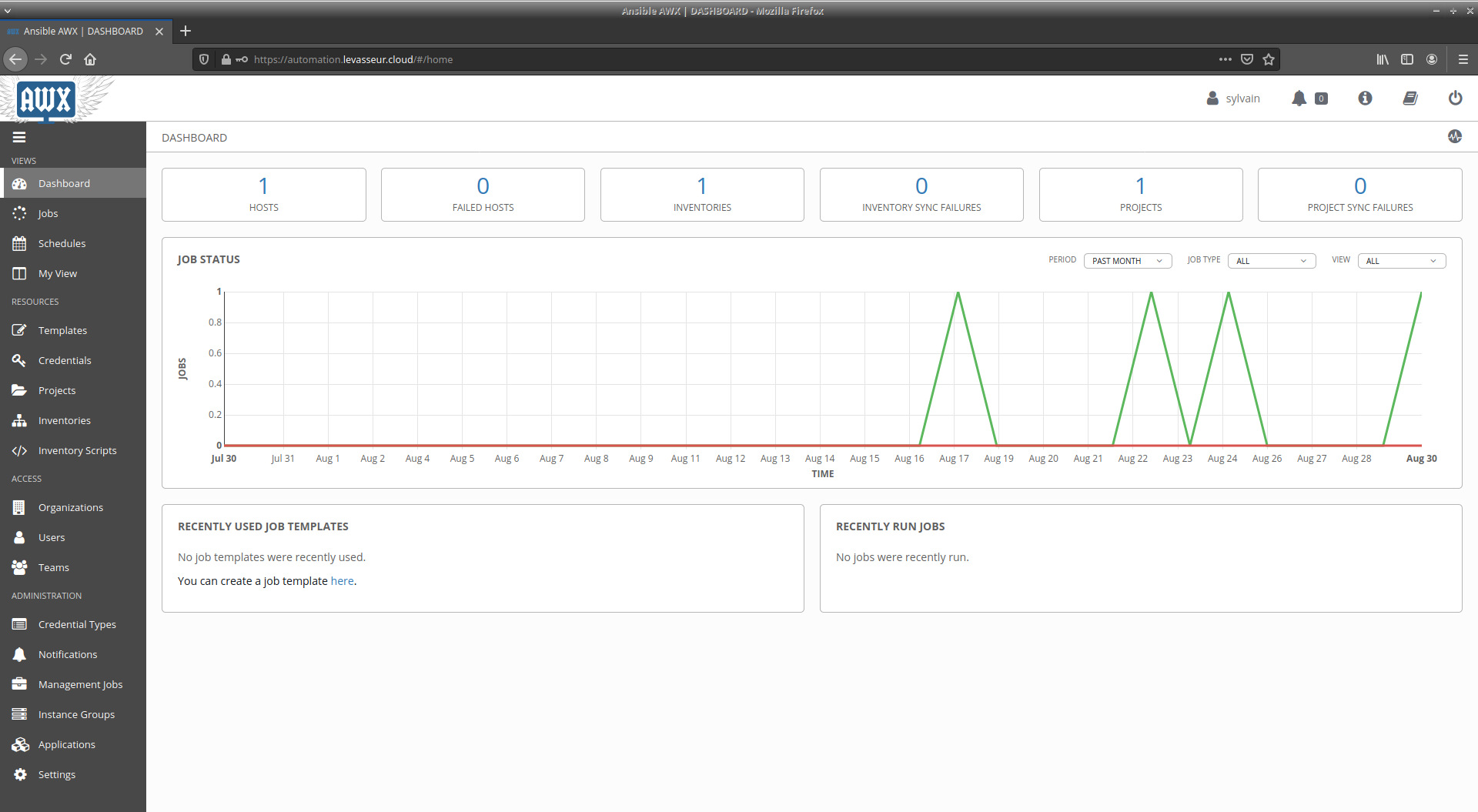
Ansible/AWX
J'ai toujous trouvé qu'il manquait quelque chose autour d'Ansible, notamment pour le scheduling de playbooks. AWX est ce qu'il me faut. Pour le moment j'utilise peu Ansible. Il faut dire aussi que vu le volume de mon infrastructure, ce n'est pas une nécessité absolue... Néanmoins j'automatise la sauvegarde des configurations de mes équipements réseau grâce à un playbook, que je n'ai pas encore mis sur AWX.
Documentation IT
Mon système informatique est documenté, surtout pour les choses que je vais probablement oublier. Actuellement la documentation est un peu éclatée à plusieurs endroits (fichiers, Google Docs, Google Keep, ...). Néanmoins je souhaite regrouper tout ça sous forme d'un wiki. Ou plus exactement, d'un mkdocs. mkdocs c'est typiquement la solution de documentation qui permet de lire ces lignes publiées sur une interface HTTP.
Généralement mkdocs s'utilise avec un pipeline d'intégration/développement continu. Pour ma part j'ai cherché la simplicité et la rapidité du déploiement de mkdocs. L'inconvénient est que je perds la notion de versioning. Néanmoins pour alimenter la documentation, je n'ai qu'à me rendre sur une page Web en particulier pour trouver une instance de VSCode en version Web pour le coup. VSCode est déjà configuré pour m'afficher le bon dossier de projet, etc. Il n'y a plus qu'à taper. À chaque enregistrement de fichier, mkdocs regénère les pages HTML à partir des fichiers Markdown et nginx sert les pages. Le workflow, le nombre d'actions requises est donc simplifié au maximum. Documenter n'est déjà pas tout le temps un plaisir. Si en plus le faire est compliqué, ce sera pas fait... Heureusement c'est simple, favorisant ainsi l'alimentation de la documentation.