Infrastructure
Hardware
J'ai arrêté les vieilles machines pas chères à l'achat (sauf pour le lab qui ne fonctionne pas 24h/24). D'une part elles coûtent très cher à opérer comparitivement aux machines modernes où les progrès en consommation électrique sont remarquables, mais aussi elles sont source de limitations/incompatibilités matérielles (ex. : pas de support pour les disques de plus de 2 To), de problèmes de sécurité (ex. : microcode CPU pas à jour, CPU plus supporté). Aussi, elles sont forcément moins performantes (à dimensions égales, densité égale, une machine moderne est plus performante) et peuvent être tout aussi source d'incompatibilité avec certaines applications modernes (difficile parfois d'avoir du software moderne avec du vieux hardware).
J'ai également arrêté les pizza boxes car ces machines de datacenter sont conçues pour la haute densité. Si on peut leur attribuer cet avantage, la contrepartie c'est moins d'espace pour le flux d'air pour la ventilation. Ainsi, il y a beaucoup de petits ventilateurs qui tournent vite plutôt qu'un ou deux gros sur un machine format tour. Ces petits ventilateurs rapides sont donc plus enclins à faire du bruit, ce qui n'est évidemment pas souhaité dans un contexte domestique.
Au final je suis parti sur deux machines, toutes deux plutôt modestes. Un serveur principal au format tour, CPU à architecture x86 en 64-bit, 12 Go de RAM puis un serveur destiné avant tout aux sauvegardes, CPU à architecture ARM en 64-bit, 4 Go de RAM (Raspberry Pi 4).
Si grossièrement les deux machines ont la même puissance de calcul, le Raspberry Pi est moins cher tout en ayant l'inconvénient de l'architecture ARM qui n'est pas supportée par toutes les applications.



Stockage
Ce sujet a été source de longues réflexions. J'ai longtemps voulu déployer un cluster Ceph (solution open source de cluster de stockage distribué) mais au moment de réfléchir sérieusement à l'utilisation de cette solution, j'ai conclu que mon besoin en scalabilité était moindre, que rajouter des disques sur une seule machine devrait suffir, que la haute disponibilité que fournissait Ceph—qui ne dispense pas d'avoir une solution de sauvegarde—n'était pas tant nécessaire, que les coûts en stockage induits par les trois copies de données étaient élevées ; qu'en conséquence déployer un cluster de stockage était disproportionné au regard du besoin et aurait généré des dépenses qui n'auraient pas été amorties.
Au final je suis parti sur du bon vieux RAID 5. Du RAID software pour ne pas être dépendant d'une carte RAID vendeur. Les deux machines ont donc respectivement un disque système à fort IOPS (SSD / carte SD) et à cela s'ajoute une grappe RAID 5 de 3x4 To raw. Le serveur principal a une carte PCI servant de contrôleur SATA avec 8 ports tandis que le Raspberry Pi utilise des contrôleurs USB3/SATA.
Je n'ai pas proprement mis en place un modèle de menace mais j'y ai réfléchi un minimum. Ainsi j'ai trouvé pertinent de chiffrer les données au repos pour ces grappes RAID. Le choix s'est orienté sur LUKS.
Système
Pour la dernière version majeure de mon système informatique, je ne voulais plus de produits Microsoft, et éviter les solutions propriétaires de manière générale. En effet, je me suis donc tourné vers du logiciel open source, notamment pour des raisons d'interopérabilité et de flexibilité mais pas seulement. Après réflexion, je pensais pouvoir faire tourner tous les services que je souhaitais sur Linux. Je voulais également une solution plus légère que la virtualisation, moins consommatrice de CPU, pour isoler les services entre eux. La conteneurisation semblait être ce que je recherchais.
Au final, pour les deux machines je suis parti sur Ubuntu Server avec Docker.
J'ai également longtemps réfléchi au déploiement de Kubernetes. J'ai apprécié le concept d'opérateurs, la simplicité pour mettre à jour les conteneurs automatiquement, et le côté haute disponibilité. Néanmoins, j'en ai conclu que la valeur ajoutée de Kubernetes était moindre quand on a que deux machines. De plus, je n'ai pas tant besoin de haute disponibilité, surtout que pour un conteneur donné, si celui-ci ne supporte pas les CPU ARM, il me faut donc des machines x86 plus onéreuses. En revanche je ne souhaitais pas tirer un trait sur le fait de mettre à jour automatiquement les conteneurs.
En somme je n'ai pas déployé Kubernetes. Je me contente de Docker et docker-compose. Et pour les mises à jour automatiques, j'utilise un outil qui s'appelle Watchtower, qui est relativement simple et efficace.
Réseau
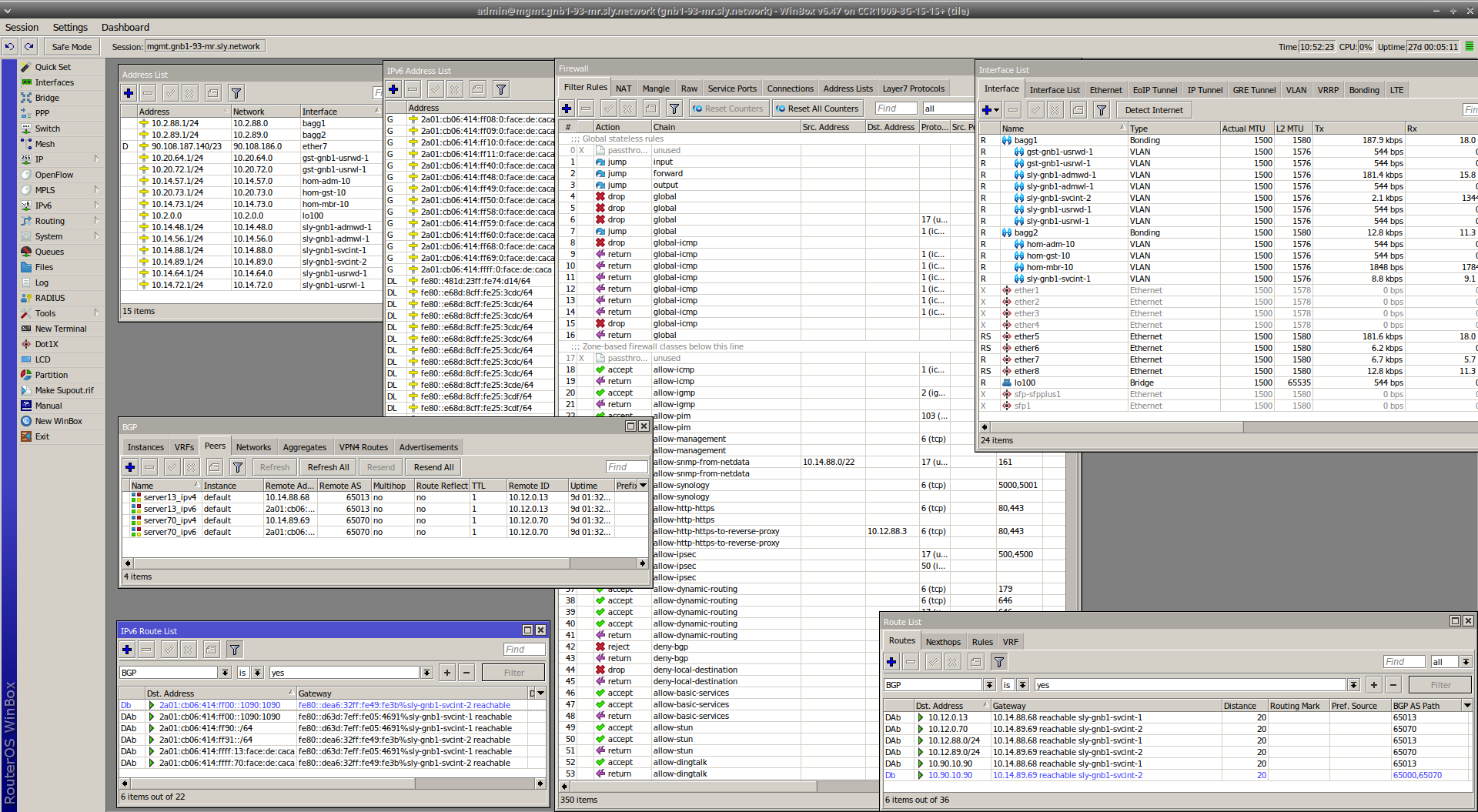
Ce sujet là n'a pas été laissé au hasard. En ce moment j'ai un routeur de site (MikroTik CCR1009-8G-1S-1S+), deux switches manageables (un par pièce ; un HPE 16 ports, un Huawei 24 ports), un modem ADSL (pas de fibre à la campagne...), deux points d'accès WiFi (un Cisco, un MikroTik).
L'architecture réseau est simplifiée par rapport au temps où j'avais des services chez OVH, où je devais donc avoir un VPN site-à-site, du routage dynamique entre les sites. Je segmentais également le trafic avec des VRF. Lite au début, puis MPLS ensuite. Mais tout ça n'est plus désormais.
Outre IP en sa version 4, j'ai récemment déployé IPv6 sur tout mon réseau. Actuellement j'ai une combinaison de SLAAC et de statique, mais j'entends remplacer SLAAC par DHCPv6 sous peu.
Le routeur fait aussi office de pare-feu. Concrètement, MikroTik est une surcouche à Linux. Ainsi le pare-feu c'est grossièrement de l'iptables. De là, j'y ai implementé le concept de zone-based firewall. Je classifie le trafic, je définis des politiques, j'applique des politiques à des classes de trafic. Au total ça donne environ 350 règles IPv4 et le même nombre pour IPv6.
Enfin, une chose intéressante, je souhaites rendre mes serveurs mobiles dans le sens où je veux pouvoir les changer de pièce, ce qui change donc le VLAN dans lequel ils sont, ce qui change alors leur adresse IP, ce qui a pour conséquence de nécessiter de reconfigurer des adresses IP un peu partout (même si je m'efforce à utiliser des noms DNS en général), à commencer par le serveur DNS. Bref, tout un chantier pour déplacer une machine d'une pièce à une autre... La solution est donc de faire du routage IP dynamique directement sur les serveurs, chaque serveur ayant à minima une adresse en /32 et /128 sur une interface loopback. Ces adresses, ou plutôt ces réseaux d'une adresse, sont donc injectés dans les processus de routage. En pratique, un serveur a plusieurs adresses de cette manière. Chaque serveur a un /24 et /64 qui lui est alloué. Les services sont tous accessibles via des adresses de ces plages. L'adresse de lien, affectée sur l'interface physique, n'héberge aucun service. Un autre avantage de cette solution, ce qu'elle permet d'avoir deux machines avec la même adresse /32 et /128. Le but étant de faire de l'anycast et de proposer des services hautement disponibles de cette manière. À ce jour le service DNS fonctionne ainsi, avec une IP anycast dédiée. Même fonctionnement que 8.8.8.8 par exemple.
Du fait de ma faible connexion Internet ADSL, et pour d'autres raisons, j'ai choisi de rendre mes services accessibles sur l'Internet au travers d'un CDN. En dehors du réseau interne c'est donc par l'intermédiaire de Cloudflare que les services sont délivrés.